

LangChain ChatGPT RAG with scraped website content
Nov 21, 2023
RAG is a technique for augmenting LLM knowledge with additional data. Often known as 'chat with your data'. In this tutorial we'll show you how to scrape all the content from any website using UseScraper, then load it into a vector store ready for Retrieval-augmented generation (RAG) in LangChain using ChatGPT.
Crawling a website's content
First signup for a free UseScraper account (you get $25 free credit on signup).
You can start a crawling job simply from the UseScraper dashboard, or via the /crawler/jobs API endpoint. Enter the URL of the website you want to scrape, feel free to input https://usescraper.com as a test. The other options can be left as is. Markdown is the default output format, which is ideal for our use case. Click "Start Job".
You can then watch the progress of the crawling job live. The results will be shown when it's complete.
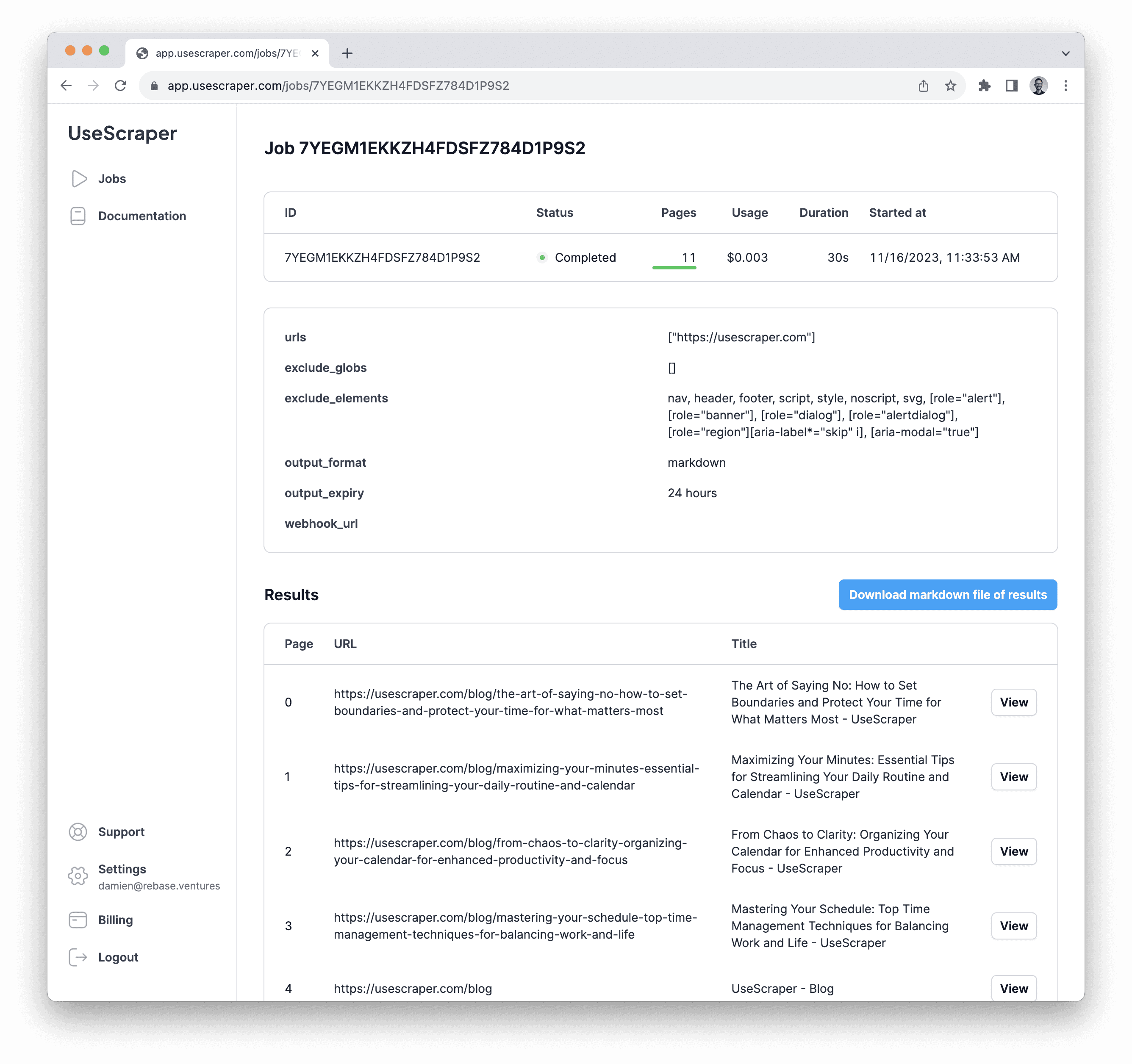
Now click the "Download markdown file of results" button to get all the content as a single markdown file. This is the file we're going to load into our vector store via LangChain.
LangChain RAG with the website content
Now we'll create a Python script which loads the markdown file with all the website content, and uses it for RAG Q&A.
First install the required libraries:
Now here's our full script to load the markdown and ask a question "What is UseScraper?" using the knowledge of the UseScraper.com website content we previously downloaded. You'll need to edit the markdown_path variable to be the filename of the markdown file you downloaded from the UseScraper dashboard (you'll also need to move the file to the same directory as you save this script to). If you scraped another website, you'll also want to edit the line print(rag_chain.invoke("What is UseScraper?")) near the end and choose a more relevant question.
Save the code to rag.py and run it with python rag.py
You'll be prompted to enter your OpenAI API key, do so and hit enter. It'll take a few seconds to load the data and get a response from ChatGPT.
Great, it works!
Code walkthrough
Let's walk through how the code works step-by-step.
First we load up the markdown_path file, and use the LangChain splitter methods to split it up into chunks.
We then load this array of splits into the vector store (in this case we use a local Chroma instance). If you'd like to see the markdown content you can uncomment the print line here.
Now we have all the website content in the vector store, we we setup the RAG chain and prompt.
Finally we send a question to the RAG chain.
Run the script to see the response.
UseScraper is a web crawling and scraping API that allows you to easily scrape the content of any website and save it in various formats such as text, markdown, or HTML. It offers advanced features and a scalable architecture to handle large crawling jobs. Additionally, it has fair and affordable pricing with no monthly fee and the ability to launch multiple crawling jobs simultaneously.
Terrific! You can extend this script to take in more prompts, or access a hosted vector store. Combine it with the UseScraper API to programmatically crawl website content when needed.
Let's get scraping 🚀
Ready to start?
Get scraping now with a free account and $25 in free credits when you sign up.

